Customer lifetime value (CLV or LTV) is a term that is used rather loosely in most organizations. When I first started working at PayPal, I was excited to see it pop up in Tableau Dashboards and on database tables. I had just learned about CLV in business school and understood it to mean the total value of a customer, taking into account some discount rate. At PayPal, it appeared at an individual customer level and I was sure that this was the CLV I had learned about in business school.
I couldn’t have been more wrong. Instead of making the rookie move of asking what CLV meant at PayPal, I started to dig around to see how this metric was being computed at the company. Surprisingly, I found out that all CLV meant at PayPal was just the total revenue to date of that customer. How bad is that? Consider the image below: the top two and the bottom customers all have a historic CLV of $40 (4 purchases at $10 each) but only the second one has a greater than $40 predicted CLV.
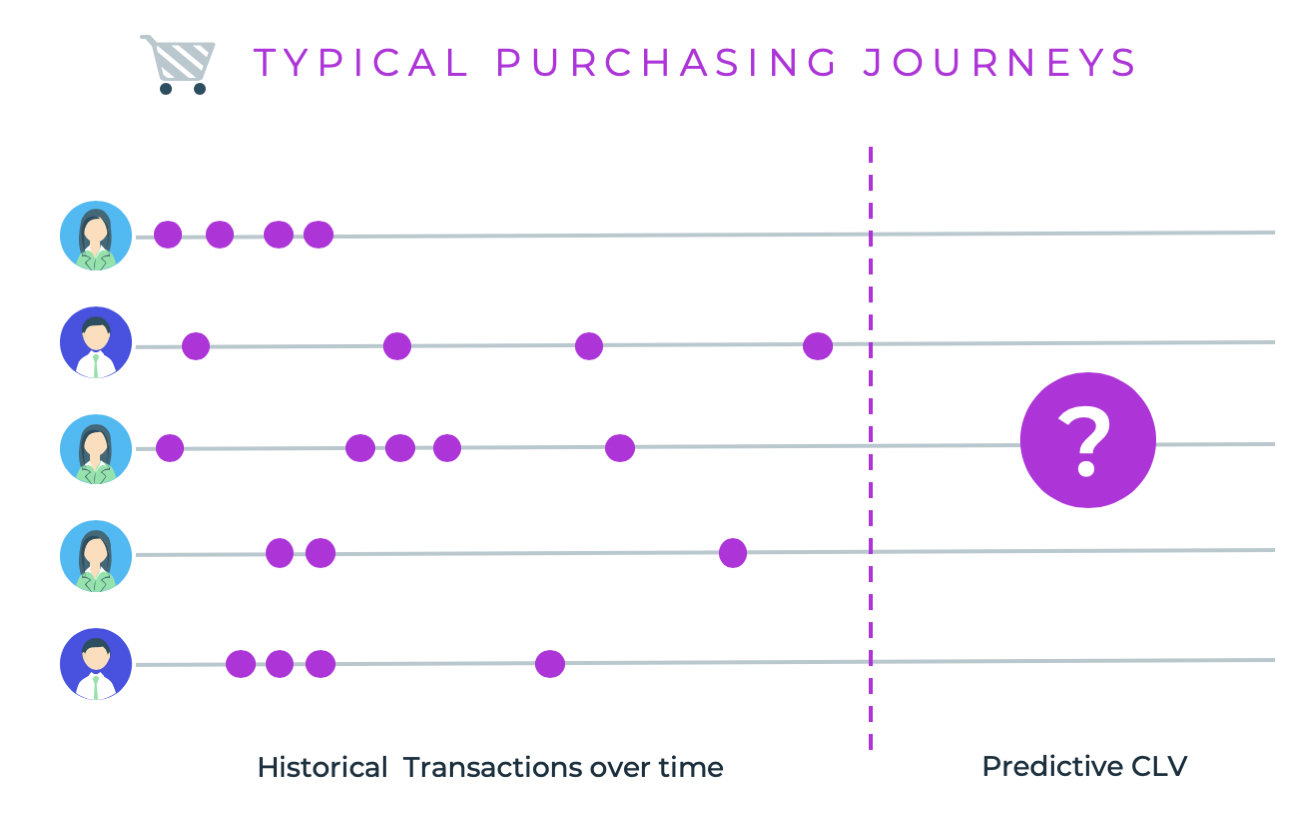
Since then, I have come to realize that customer lifetime value will mean something different depending on your organization, and it may not even be predictive. It may not represent the customer’s total lifetime.
If the data team at your organization or a vendor you have hired provides CLV or LTV, here are the questions you must ask:
Is the CLV at the aggregate level or individual level? If it is aggregate, is it the mean or median?
This matters because it’s fairly easy to compute CLV at the aggregate level. At the aggregate level, customer lifetime value can give you a sense of how healthy your business is. Many models, including the one that you learned in business school, compute CLV at the aggregate level for each cohort.
Pro-tip: You can do back-of-the-envelope CLV calculations by calculating average order value per month and dividing by your monthly customer churn rate.
At the aggregate level, it may be important to differentiate between mean and median CLV. If your dataset has outliers (typically test accounts or wholesale buyers who follow a different sales process), using mean CLV can be problematic — you may end up over or underestimating the CLV of your typical customer. Solutions to this problem may include using trimmed mean or median CLV instead.
Per guidance from our advisor Dan McCarthy, we also advocate that people look at mean CLV. This is because the vast heterogeneity across customers implies there will be some super duper customers and we want to embrace them, not ignore them. And in some industries, such as mobile gaming, median CLV can be misleading. Median CLV in free to play gaming companies will almost always be $0, for every single cohort, which will not be diagnostic.
While aggregate level CLV can be useful if it’s calculating correctly, your marketing executives will be much better served with individual level CLVs, or CLV estimates that are custom tailored to each and every one of your customers’ historical spending patterns. With individual-level CLVs, you can tease apart what it is that makes your best customers different from everyone else, and incorporate that information to supercharge the profitability of your next customer acquisition campaign. Aggregate CLVs can’t allow you to do this because everyone being aggregated over will, by definition, have exactly the same CLV.
Is CLV historic, predictive or some combination?
If CLV is being provided at the individual level, you want to make sure the CLV is predicted (i.e., includes the value you expect to get from him or her in the future), and not just historic. The problem with relying on historical profit/revenue is that you can misclassify recent customers. For example, if you acquired a customer last month, you cannot compare this customer to a customer acquired one year ago — unless you can predict the one-year behavior of the recent customer.
How much of CLV is already observed vs predicted future revenue/profit?
The next question you must ask is if this is a future prediction of CLV as of today or if it is from another reference point in time. The danger of using only future-predicted revenue is that you can no longer compare future-predicted revenue of a highly active current customer with a previous cohort of customers. For example, if you compare an inactive, high-spend customer from a year ago with an active low-spend customer, you may be comparing apples and oranges. Computing predicted lifetime value from a variable reference, such as the beginning of a customer’s relationship with your business, makes more sense.
If the CLV is predictive, how far into the future does that prediction extend? Does it make sense if a customer has a lifespan of 20 years?
For any predictive CLV, you should know if the CLV is truncated or if it is incorporating value that you expect to generate into the indefinite future. If you are not using truncated CLV, several possible problems can arise: People may not live as long as you may have predicted, or an unnecessarily long forecasting horizon may not be relevant to the business. For example, we typically see clients wanting good short- and long-term insights by looking at 1, 2, 5 and 10-year predictive CLV.
Can the CLV account for varying tenure of customers?
Imagine you are computing CLV for each customer as of today, looking one year into the future. To compute CLV, you might take into account the full history of every customer. Given this, it may not make sense to compare customers who joined five years ago with someone who joined two years ago. This is because the total time consideration for the first customer is six years (five years of history and one year of prediction) and for the second customer is three years (two years of history and one year of prediction).
Pro-tip: Ask your data scientists to account for this by varying the length of the future prediction window so that total prediction time is held constant.
For customers whose observed lifetime exceeds the total prediction time, you should probably only bake in the value generated over the total duration of the prediction time, and leave off all value generated after that point. This is the only way that the resulting CLV figures for those customers will be comparable to the others.
Does it make sense to include or exclude super old customers?
It’s also important to consider how far back you should go to compute lifetime value. Imagine if you were a company as old as Coca Cola. Should you include customers in your model who started consuming the beverage back in 1920? Are those customers still relevant? This is an extreme example that I have used to prove a point, but how about a company like Apple? Should a customer who joined to buy the original Mac be considered in the CLV model? There is no established answer to this, but generally, we suggest considering a relevant business window that goes back at least a few years. This will help the model understand seasonality, but is not so far back that the business and customers are no longer relevant.
Does the predictive CLV number change often and, if so, how can you track changes to CLV?
There is extensive academic research trying to assess the impact of marketing and external influences on CLV. Professor Anand Bodapati of the University of California, Los Angeles has done a considerable amount of research on this topic. He suggests that predictive lifetime value will change based on external influences. Because of this, you should ask your data team to compute predictive lifetime value on an ongoing basis, instead of one time for each customer. It will also be important to measure how your marketing, pricing, and product launches impact the CLV number over time.
Final Thoughts
Given the ambiguity around CLV and its use cases, you should work closely with your internal data team to consider these critical questions before widespread use of this metric. At Retina we obsess about getting these detailed questions right and if you have questions or want to think through your CLV strategy, please email us today at [email protected]