If you’ve been trying to leverage the power of data science – but, like many teams, feeling overwhelmed and unproductive — you’re not alone. Data science is difficult for many reasons and teams are under constant pressure to deliver insights quickly, despite the field’s inherently complex nature.
At Retina, we think of data science like cooking a meal: The insights generated depend on the specific ingredients and order of preparation. Then, once a new dish has been created, it can be captured in a Data Science Recipe, to refer to the next time, and to share with other chefs. Recipes capture the elements chosen to best address a problem, and can be re-used to quickly deliver results.
In this post, we tackle the 5 key elements of Data Science Recipes. We also point out how some of these ingredients, when combined, yield yummy results. Note that, as in cooking, not all ingredients are used for every recipe.
The 5 Elements of Data Science Recipes:
- Data
- Problem
- Model
- Algorithm
- Validation
Introduction
As everyone knows, the first element of data science is data. Data often appears as a set of disjointed and messy tables, which may have missing values or weird features. There’s usually a lot of work involved in preparing, organizing, structuring, and loading data to the point where it’s clean and ready to be utilized in a science project. Indeed, keeping your data in top shape for your pipeline could require whole teams of DataOps engineers who leverage DataOps principles.
Next is the problem: This should be a well-crafted business question that can be answered using the available data. The tricky part is identifying levers you can pull and how those actions affect your outcome. My background in optimization theory conditions me to refer to these levers as variables. Crafting a good problem consists of choosing success criteria and operating constraints as a function of these variables.
We use a model to capture assumptions about the cause-effect relationship between variables and metrics in our science sandbox. Machine learning scientists and engineers will discover that their modeling intuition is very strong — indeed, model choice is extremely important in machine learning. A common science project will hold data and problem as fixed, and choose one model from many that fits best. (Refer to the validation paragraph below for more information.)
An algorithm is the process of finding a solution to our problem that follows rules dictated by our model. Algorithms are often iterative (for example, a gradient descent model finds the minimum of a function through iterative operations), but they can also be analytical. Some algorithms guarantee convergence; others don’t. Some provide solutions guaranteed to be the best, but most don’t. Algorithms often accompany models in machine learning packages so that data scientists needn’t worry about them in their day-to-day responsibilities.
Finally we have validation, which consists of benchmarks, iteration, and documentation. The popular practice of n-folds cross-validation falls under this jurisdiction. The purpose of validation is to document outcomes under various scenarios, such as splitting data into train/test sets or the random initialization of an algorithm. A validation expert will imagine what can bend and break, then craft scenarios and define “good” quantitatively — a role akin to that of a quality assurance (QA) engineer.
Data Science Recipe: Targeted Marketing Budgets Using CLV
To see these pieces in action, let’s imagine we’re data scientists working for an eCommerce company. We know our stakeholders (marketers) are interested in identifying smart ways to retarget the company’s most valuable customers. We also know that Retina AI just augmented our data with customer lifetime value (CLV), an astute metric for quality comparison amongst customers.
Realizing that not all customers are created equal, we imagine each customer as having his or her own micro-budget for retargeting and promotional costs. This way, a stakeholder may choose to invest more to engage the most worthy customers on a discretionary basis. So we’ve identified our problem as the assignment of each customer’s budget (the variables) to maximize total value.
But we have a conundrum: How does additional marketing spend affect future realized customer value (purchases)? We should expect that more marketing touches increase the likelihood of the next purchase, but with some sort of diminishing returns. In this case, pulling from our knowledge of marketing science, let’s assume a customer’s value grows logarithmically with engagement spend and maxes out somewhere around their predicted CLV. This model makes it possible for us to account for higher value from highly engaged customers, in a way that we hope represents the real world.
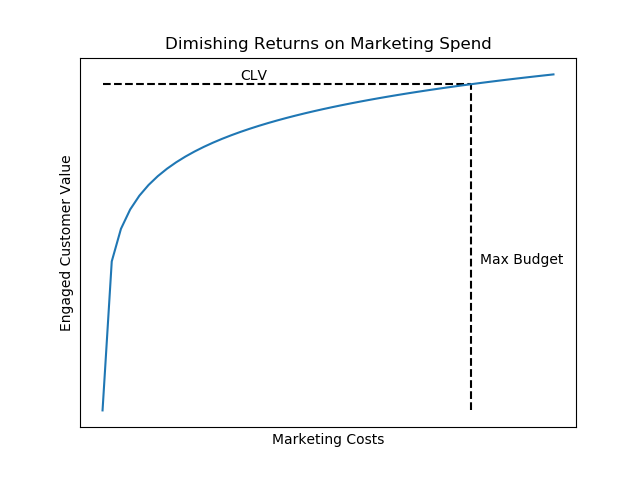
So now we’re studying the problem at hand: to maximize customer value as a function of marketing spend using CLV data, subject to our budget constraints. Fortunately for us, we were creative enough to craft our model to be analogous to the “water-filling problem” (Boyd 2004, page 245), which utilizes a well-known analytical algorithm.
Finally, we test performance two ways. First, we imagine each customer receives the same micro-budget and compute total customer value using our model that accounts for diminishing returns and variations in customer value. This is our benchmark, or baseline, for business as usual. Then, we compare this to our (much higher) optimal value under a smarter choice of personalized budgets. To be even more certain, we devise an A/B test to empirically validate the added value.
More Examples of Data Science Recipes
Below, I outline how we use our 5 elements of data science framework across a number of data science projects at Retina.
First and foremost, we use the following recipe to fine-tune CLV scores for our clients: We use transaction history (data) to learn a buy-’til-you-die paradigm (model) that’s tuned to predict purchases (problem) for a year’s worth of customer behavior (validation). Our scalable and distributed infrastructure even allows us to use the higher-performance MCMC method (algorithm). We’re now testing how other models (for example, a recurrent neural network) perform when additional data (such as profiles and clickstreams) is available.
As another example, consider feature selection more generally. Most features will be redundant or lacking signal to the point of being misleading. To reach the goal of identifying a subset of important features, we craft a simplified data science pipeline, hold all elements fixed except data, and use the validation step to quantify the predictive power of various feature subsets. A similar approach can be used to test out which model performs best.
A very common mistake is to confuse problem with model (goals with assumptions) or the model with an algorithm (assumptions with a widely accepted solution method). To exacerbate this common mistake, automated machine learning tools and packages (especially ones involving neural networks) typically obfuscate the algorithm from the model. You may even mistake the minimization of model error with the solution to a problem.
As a final example, our team has been playing around with the “diet problem”: Given nutritional and cost info for various foods (data), we seek the cheapest diet (problem) so that our health needs are met (model). Fortunately, this problem can be posed as a linear program, so a solution is readily available (algorithm). Depending on the inventory of our virtual grocery store, the validation portion should be fairly fun!
Conclusion
As our company grows, we’ve found it essential to organize, templatize, and automate as much of our data science work as possible. As we add more team members, we are also finding that breaking down data science into these elements provides a natural path to growth, development, and mastery. Thinking of projects as the development of Data Science Recipes helps us to build internal expertise and quickly generate results.
Also… Our team is scaling! If you’re interested in joining us, please check out our careers page.