This is an opinionated guide on how to use DataOps to deliver business value from data. It is a prescriptive fix for organizations struggling to realize expected returns on their data science and analytics investments.
Origins of DataOps
In 2015, Gartner released a report that stated that 60% of data projects in the U.S failed to deliver their desired business outcomes. These failures were attributed to some sort of process failure, a technology failure, or even a people and culture failure. Two years later, in 2017, the failure percentage was amended to 85%. It was right around that time that a group of experts studied these process, technology, and culture issues and created a prescriptive methodology for delivering business value from data that is both fast and accurate. That methodology is called DataOps.
DataOps Manifesto
The DataOps manifesto can be summarized into five core principles. These principles capture DataOps according to its creators. They can be thought of as blueprints for good decision-making during data project planning and implementation.
- Individuals and interactions over processes and tools. It is best to allow operating procedures to form naturally in an organization and only standardize them into rigid processes once fully formed.
- Working analytics over comprehensive documentation. Take a minimalist approach to data project planning and ensure that tasks tied directly to end-customer value are the most highly prioritized.
- Customer collaboration over contract negotiation. When gathering requirements from end-users, do not focus on defining expected deliverables from day one. Instead, work with end-users to identify what success really means to them.
- Experimentation, iteration, and feedback over extensive upfront design. This is very close to the Agile methodology. Focusing on fully scoping out projects early will inevitably lead to failure and frustration. It is better to scope out small experimental releases and get feedback from end-users multiple times to make sure that the final product aligns with end-users’ expectations.
- Cross-functional ownership of operations over siloed responsibilities. It is better to have multi-functional product-based data teams working together daily than to have subject matter expertise based functional teams.
Process
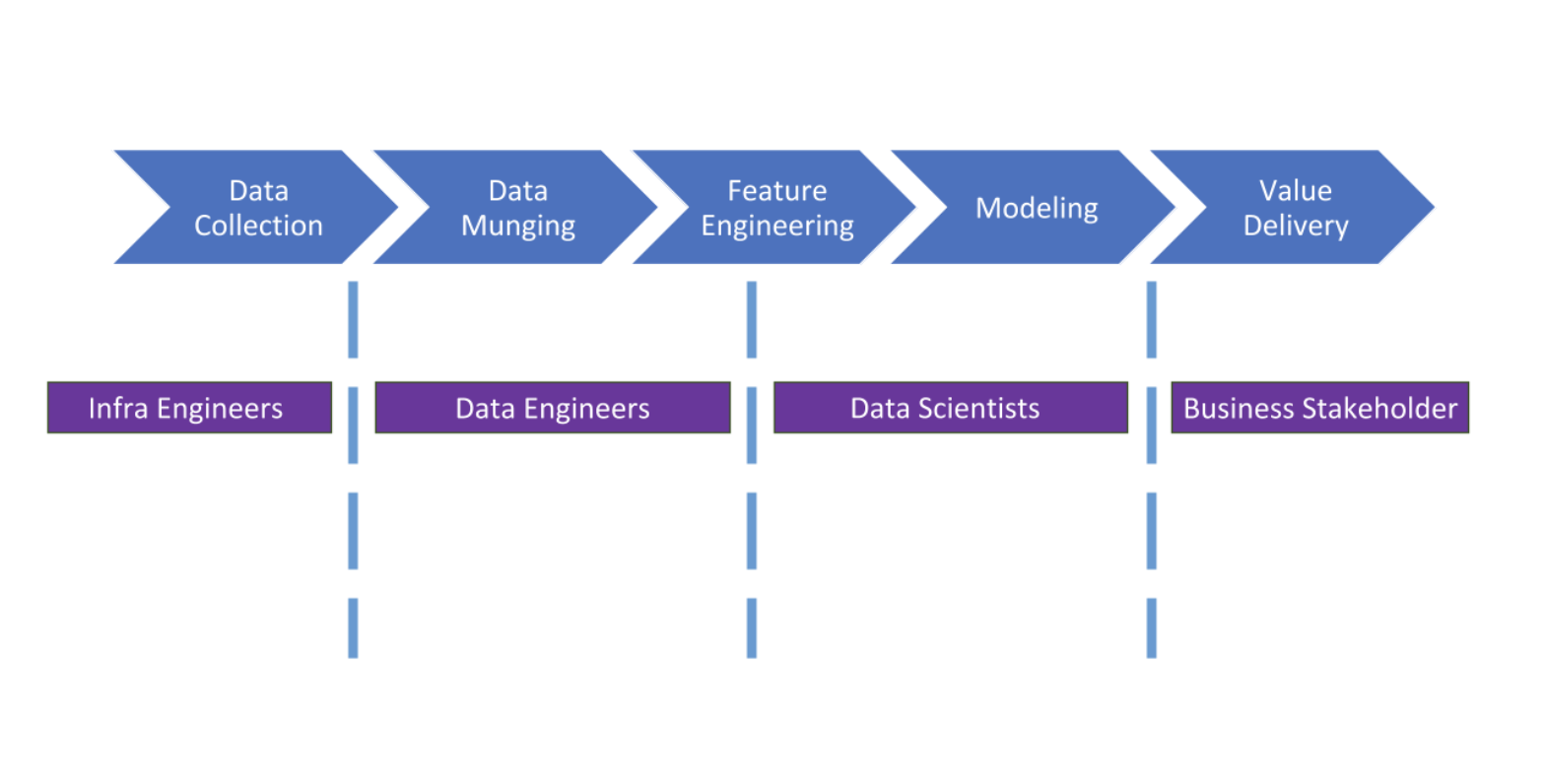
The figure above shows a common process for delivering data products. It consists of several processing steps that depend on one another and individual specialist teams responsible for each process step. When data projects are run using the process above, unavoidable overhead is created when transitioning between process phases. This overhead, represented by the blue walls between each process step in the figure above, forms when one team with no access to one side of the process tries to interface with another team with no access to the other side of the process.

Here’s an example of the hand-over wall between the data processing phase and the model development phase. This may be familiar to most readers.
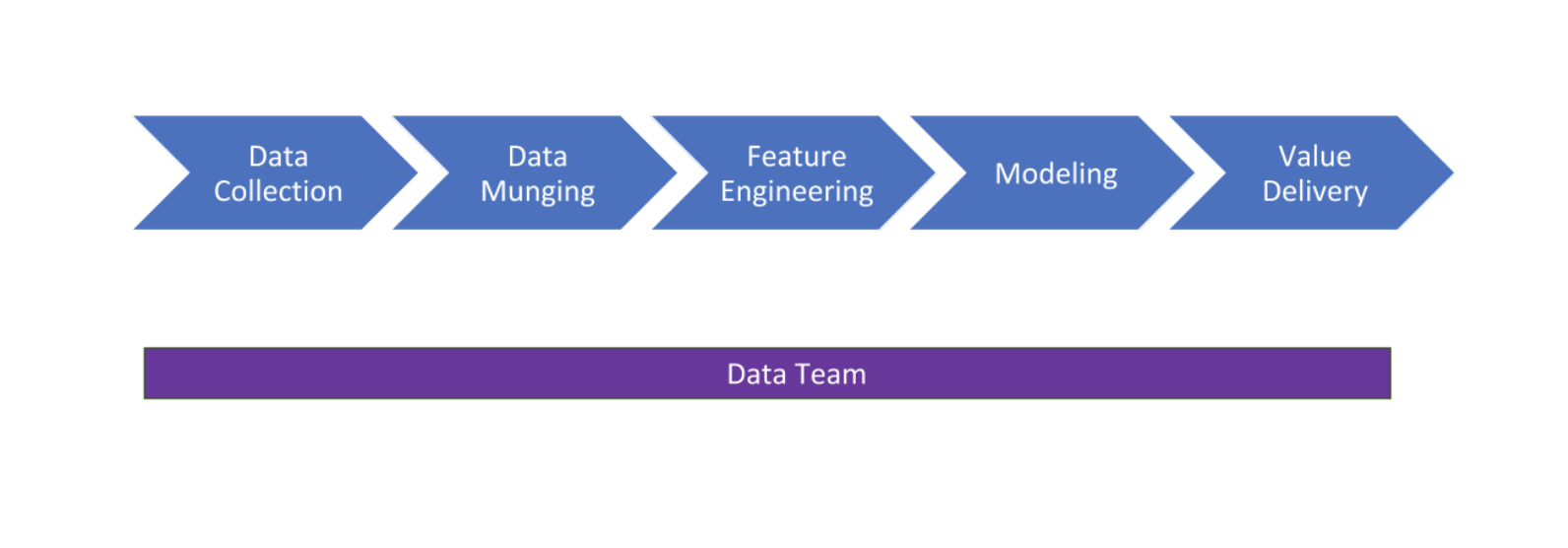
The DataOps solution to the hand-over problem is to allow every stakeholder full access to all process phases and tie their success to the overall success of the entire end-to-end process using the following process takeaways:
- Value delivery is a sprint, not a relay. Treat the data-to-value process as a unified team sprint to the finish line (business value) rather than a relay race where specialists pass the baton to each other in order to get to the goal. It is best to have a unified team spanning multiple areas of expertise responsible for overall value delivery instead of single specialized groups responsible for a single process phase.
- Business value should be everyone’s north star metric. Ensure that all team members regardless of specialization see business value delivery as their ultimate north star goal. Avoid competing individual objectives whenever possible.
- Time to value over magnitude of value. The most important metric to track for value delivery is time to value. This should take precedence over magnitude of value. End-users would prefer to receive value faster even if it’s small than to wait a long time and receive some magnificent cathedral of value.
- Value is unlocked only at the end of the process. Recognize that processes are bottlenecked by their slowest phase and that optimizations to any other phase will likely not solve the bottleneck. Be systematic in identifying and addressing process bottlenecks as early as possible to ensure that the value delivery process is as smooth as possible.
Technology
A well architected data infrastructure accelerates delivery times, maximizes output, and empowers individuals. The DevOps movement played an influential role in decoupling and modularizing software infrastructure from single monolithic applications to multiple fail-safe microservices. DataOps aims to bring the same influence to data infrastructure and technology. When designing and/or assessing data infrastructure, consider the following technology takeaways:
- De-risk and encourage change. Data infrastructure should be designed to accommodate and encourage frequent changes without the need for specialist gatekeepers, extended deployment cycles, or cumbersome processes.
- Decouple and separate compute from storage. Stateful data services add unneeded complexity to data infrastructure systems and make reproducibility difficult. It is best to focus on design simplicity, modularization, and separation of concerns between storage and compute infrastructure.
- Track and version control everything. Version control should not just be reserved for code. All entities, along with their relevant meta-data, in the journey from raw data to value should also be tracked and version controlled. This includes intermediate datasets, machine learning models along with their metrics and results, and finally the relationships between each entity. A robust tracking and version control system is essential for ensuring quality, trust, and reproducibility of business value delivery.
- Have reproducibility by design via functional programming. Adherence to functional programming principles such as immutability, state discipline, and referential transparency should be encouraged as they lend themselves well to ensuring both reproducibility and scalability of data deliverables.
- Discourage gatekeeping and encourage democratization. Unnecessary gatekeeping slows down value delivery and fosters a culture of distrust amongst data teams. Data infrastructure should be designed to avoid the need for gatekeepers and instead leverage automation to ensure quality, security, and compliance.
People
At its core, DataOps aims to promote a culture of trust, empowerment, and efficiency in organizations. A successful DataOps transformation needs strategic buy-in starting from C-suite executives to individual contributors. It cannot be implemented by solely focusing on changing processes, adding tools, or overhauling infrastructures. Consider the following takeaways when rolling out DataOps in an organization:
- Leverage automation as a tool to bridge skills gaps. Unifying data functions and having cross-functional teams work together across the entire data-to-value process stages may seem daunting. Automated processes and helper tools should be used to bridge any skills gaps amongst team members and ensure quality. For example, an automated data testing and validation framework may be leveraged by data scientists to assist with bridging their skills gap in the data munging process phase. Similarly, an AutoML framework may be leveraged by data engineers to assist with bridging their skills gaps in the modeling process phase.
- Organizational silos are blockers to collaboration. Preventing organizational silos requires frequent strategic intervention and organization design changes. Silos usually form naturally as organizations grow in size and complexity. Silo formation must be identified and handled accordingly as the organizational complexity increases.
- Changing culture requires motivation, education, and time. DataOps is, first and foremost, about people . It is essential that every member of the data organization recognizes the strategic vision and how it aligns with their own career goals. The best way to ensure that a strategic vision gets implemented is to align it with the personal goals of the individuals in the organization and enable them the processes and tools required to achieve their goals.
Following the DataOps principles described in this guide and taking strategic decisions based on data will inevitably lead to higher business profits, more satisfied customers and happier data teams.