This article shares the common issues that data teams face when moving their models from development to production systems and how these issues could be avoided.
Problem 1: Mismatched metrics
Let me tell you one of my favorite stories. The story highlights my dear data scientist friend Bob and his journey of converting his machine learning model into production. 
This is Bob. Bob works as a data scientist for a video conferencing business called “Soom”.
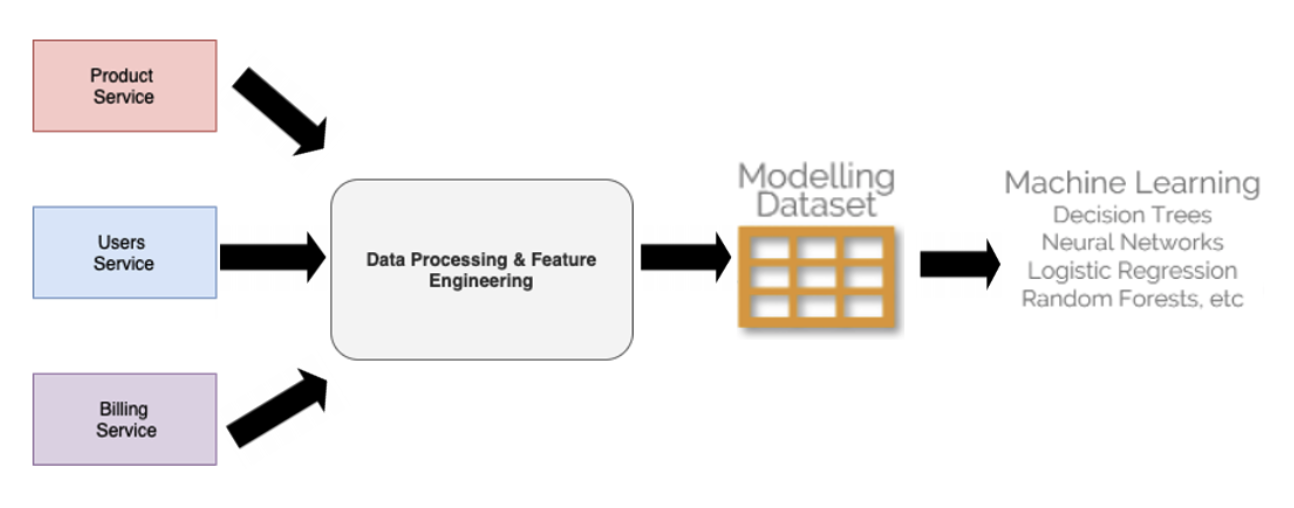
“Soom” offers its customers a suite of video conferencing products for a variety of online events, including online meetings, conferences, webinars, and meetups. They have two main product offerings: A free video conferencing web product with a 45-minute limit on meetings and a $20/month video conferencing web product with no time limit on meetings.
One day, Bob’s manager asked him to develop an upsell prediction model that predicts if a customer that recently signed up for the free product will eventually upgrade to the paid product within the first 90 days of their lifetime.
So, Bob thought, this is going to be a piece of cake. The business problem translates very well into a supervised learning problem with two label classes.
- Users that signed up for the free product and purchased the paid product within 90 days
- Users that signed up for free product and did not purchase the paid product within 90 days
He spends the next two weeks collecting and cleaning the data he needs from different sources across the business. He collects subscription data from the billing service, demographic data from the users service, and usage data from the product service. After collecting and cleaning the data, he generated a dataset of features to use for modeling. He even managed to get a few iterations of model training, testing, and validation in.
By the end of the two weeks, he had a simple working model with an accuracy score of 0.86, a recall score of 0.77, and an area under the curve score of 0.88 in validation. Not ideal, but still pretty promising.
During his two-week check-in, Bob’s manager asks, “How’s it going Bob? Do we have a model that’s ready for production yet?” and Bob responds, “I managed to develop a simple model that achieved an accuracy score of 0.88 in my tests. These are great preliminary results. I’m sure I can get my accuracy up if I try a few more advanced modelling techniques.”
Another two weeks pass, in which Bob tries out a couple of ensemble model configurations and he even implements a state-of-the-art deep neural network model he had read about in a recent research paper. By the end of the two weeks he had upped his validation performance scores to 0.90 accuracy, 0.98 recall, and 0.99 area under the curve.
During the next two-week check in, Bob’s manager asks, “How’s it going Bob? Do we have a model that’s ready for production yet?” and Bob says, “I managed to increase the model accuracy by 10%, and I believe that with proper hyper-parameter tuning, I can squeeze out a few more percentage points.”
You see Bob is an exceptionally talented data scientist that takes pride in making the most accurate models for the business. It’s what sets him apart from all the other mediocre data scientists that throw logistic regressions at every problem and call it a day.
In just a couple of days, Bob had improved the model performance even further. It was finally ready for prime time. Or so he thought. That week, the product strategy team decided to shift their product catalog and get rid of the free product entirely. The business no longer needed Bob’s model since there was no upselling anymore.
Lesson 1: Don’t chase perfection: Good enough, fast enough
Businesses nowadays need to move and adapt very quickly. And data scientists need to keep up with the pace of change of the business. If the marketing team and the engineering team are operating in two-week cycles, the data science team can’t afford to have four- or six-week cycles without risking falling behind.
Many data scientists are wired to chase model performance metrics like accuracy and recall. However, from a businesses perspective, it doesn’t matter how high a model’s AUC score is in validation. What matters is the number of customers that the sales team managed to upsell while utilizing the model.
Good enough here depends on the problem at hand. If you are developing a customer acquisition model, then you may be able to get away with slightly below optimal performance, but if you are using the model to detect financial fraud or diagnose patients in a hospital, then the bar is higher.
Problem 2: Hidden dependencies
Okay, back to our story. Let us pretend that Bob actually followed lesson 1 and went on to deploy his first, simple, good enough model to production with some help from his machine learning engineer teammate. They work with the sales and marketing teams to set up an A/B test where a special discount code is sent to free product users who are otherwise predicted not to convert into paid users.
They package the model along with its dependencies in a docker container and deploy it as a microservice with an API endpoint to the a staging system, where they can safely test it before it goes into production.
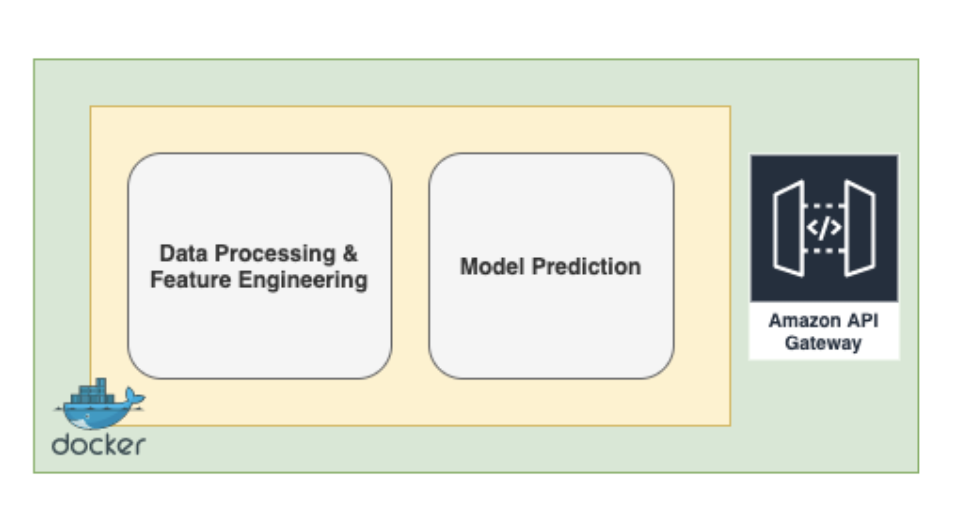
It passes all the tests and it gets deployed successfully to the live production system. Two days later, the poor machine learning engineer gets woken up in the middle of the night by the company’s production monitoring slack-bot notifying her that the model service is no longer returning any predictions. An incident investigation is launched and many hours later the culprit is found.
It turns out that the product team added a new event type to their product service: a festival event.
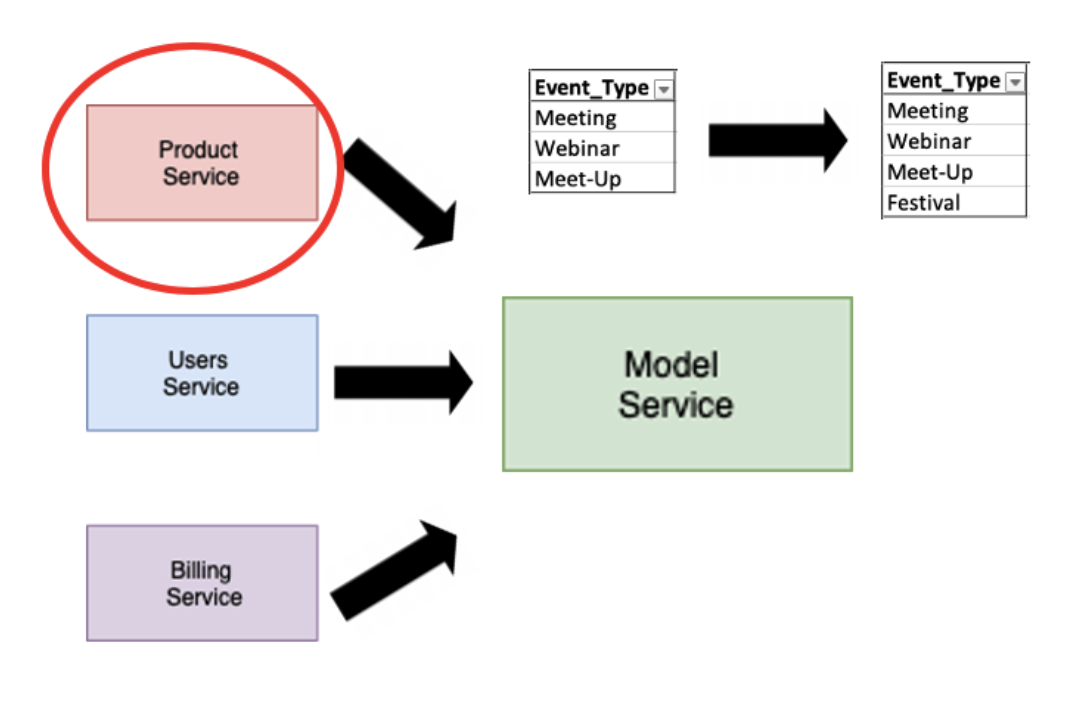
You see Bob’s model uses event type as a feature, and when he developed the model, he set it to accept and encode every available event type category to a numerical value using a technique called one-hot-encoding. This is an effective technique for dealing with categorical features when developing. However, it can cause model features schema to change every time a new category is added to a dependent column.
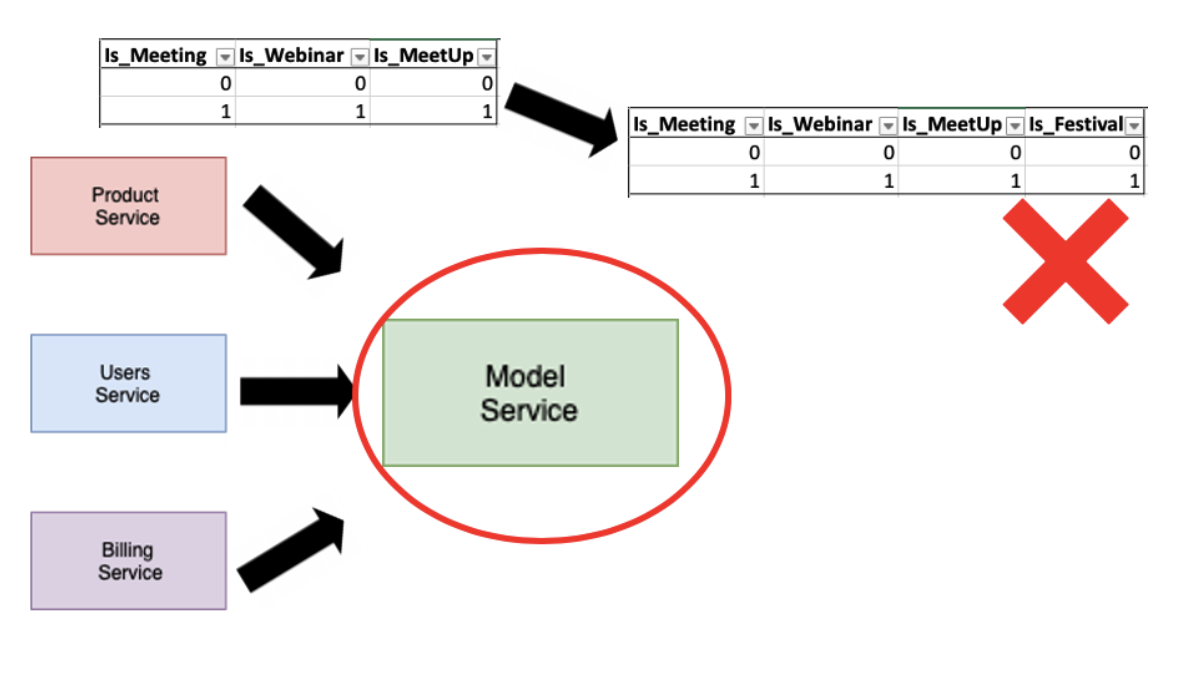
Lesson 2: Ensure feature creation is robust against changes in the underlying data.
Machine learning models don’t just have code dependencies, they have data dependencies as well. These are far more difficult to catch and document across the business. In Bob’s case, the product service didn’t even have to introduce a schema change to break the model service; a simple categorical entry addition was enough to break the model service.
When preparing models for production, make sure they are robust against future changes in the data by using defensive coding techniques. A model service should follow the Robustness principle. It should be liberal in what it accepts as inputs, have data preparation code that can handle inaccurate inputs without failing, and rely on event logging to track instances when unexpected inputs occur.
Problem 3: Performance in production not matching performance in development
Let’s assume that Bob and his data team addressed the hidden dependencies issue and redeployed their model to production with the appropriate safeguards.
When you have a model in production, you can re-evaluate the model performance immediately after deployment using more recent data. So, Bob validates that this model is working in production by testing with a fresh production dataset. He notices that the model accuracy drastically dropped from 0.85 to 0.55, in just a few days. So, what happened?
Lesson 3: Beware of locality, seasonality, and sampling issues.
It is not easy to find the underlying issue for mismatches between development and production. Common examples include:
- Locality issues: Generalized models do not usually localize well to specific subset distributions. This applies to both geographical and temporal locality. Training a model on an international customer base may not necessarily perform well predicting on the U.S customer base. Locality is not just limited to geographic locality. Temporal locality could be an issue as well. If a model is trained using five years of past data but the business had some major pivot two years ago, then there could be little to learn from the older data. In fact, it could constitute more noise than signal.
- Seasonality issues: Depending on the amount of historical data available, it may be difficult to account for long horizon seasonality effects. For example, in typical retail datasets, multiple years of data is needed to capture the seasonality of the holiday season.
- Sample distribution versus population distribution: If the sample data does not accurately represent the population data, a mismatch occurs between the shape of the distribution of samples in production and the samples in development, which can affect the model performance. To mitigate this issue, ensure that samples used to train models are truly random. Avoid horizontally slicing datasets into train and test sets; use random sampling techniques instead.
Problem 4: Model drift
Bob managed to redeploy a more representative model to production, whose accuracy metrics matches that of development. His manager is extremely excited and, after successful A/B testing, the business starts to leverage the model predictions to supercharge marketing to free product users who are otherwise predicted not to convert into paid users. The marketing initiative performs really well during the first few weeks but starts to rapidly degrade. What happened?
Lesson 4: If you deploy once, you will deploy multiple times.
All models drift over time. In fact, good models will drift faster. You see businesses use the prediction of ML models to take some actions to change the business. So, the snapshot of the business that the model was trained on changes and thus model drift occurs.
One key difference between software development and machine learning development is that software automates business decisions, while machine learning takes business decisions. A data driven business is expected to take actions based on the data.
Problem 5: Online learning and monitoring
Having learned from the previous lesson about deploying multiple times, Bob and his data team work together to set up an online learning system where the model is versioned, its performance is monitored, and a retraining process is automatically triggered and evaluated every time the production model performance degrades past some predetermined level.
This automated system is the typical go-to in industry today. It allows data teams to focus on being as impactful to the business as possible by developing new models that address different business issues rather than spending time maintaining and re-tuning existing production models.
We would expect the model performance over time to look like the curve below when an online learning technique is used.
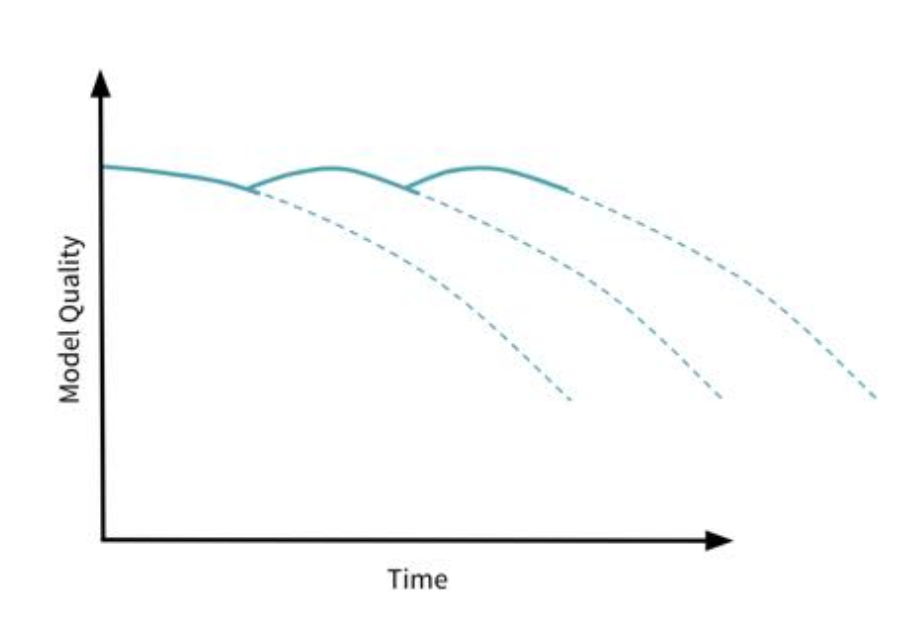
However, in some cases, such as the case with Bob’s team, the true model quality over time graph looked something like this:

Lesson 5: The model performance metrics used in development may not be sufficient for performance monitoring in production.
First, let’s remind ourselves of the model. It is predicting if recent customers are going to purchase in the first 90 days of their lifetime, which means that to get the true label for a model prediction, we would have to wait up to 90 days. Therefore, a monitoring system based only on accuracy, recall, and AUC metrics would take a staggering 90 days to identify drift levels.
One possible solution to this issue is to monitor the distribution of predicted label classes, regardless of their true label status.
If the distribution of the predicted labels starts to change in production to that of development, then that could be a good proxy indicator for the presence of model drift.
At Retina, we build models for our clients to predict customer lifetime value early in the customer journey. If you want to learn more about CLV and moving models from R&D to production, let’s chat.