Do you have server infrastructure pain? Are your engineers spending more time managing servers than they are enabling more business value? Are you paying for resources that you aren’t using, just in case you need them? If so, then you need serverless.
Serverless enables modern tech companies to meet increasing infrastructure needs efficiently. But what is it? And how does one use it? In this post, we explore what serverless is, and how we use it at Retina to enable a modern AI startup.
Serverless Principles
There are multiple competing definitions of what serverless is. We think of it as being defined by a set of key principles which embody the value of serverless systems, and go beyond any specific technology or service.
- Abstracted servers and server processes
- Managed high availability
- Fine-grained billing by actual usage
By choosing serverless solutions with these properties, we enable our engineering team to spend less time on infrastructure, and more time on building out new features.
1. Abstracted servers and server processes
Unlike what the name would imply, serverless systems actually do run on servers. What a serverless system does do, is to abstract away the servers. That is, some layer or framework is provided such that obscures the details about specific machines running in datacenters. All of the worries that go into managing those machines are then abstracted away.
Public cloud providers abstract away the hardware and networking aspects of running a datacenter. Indeed, no longer having to deal with cooling systems, redundant power and networking, and the sunk cost of hardware, was a giant boon to the technology sector. But one still needs to administer operating systems, ports, and permissions on a typical virtual machine. Serverless systems go beyond that.
Container orchestration systems such as Kubernetes abstract away much of the handling of allocating and reliably managing many servers and processes. Kubernetes pioneered the idea of going from individually administered “pet” servers, to swarms of code-orchestrated “cattle” servers. But one still needs to think about allocating the right number of servers, managing service discovery, and cluster management. Serverless systems go beyond that.
In a serverless abstraction, there is no representation of the server, or operating system, at all. The abstraction takes care of scaling up and down the servers needed to execute the needed code in a manner that is completely transparent to the developer. This means a whole host of worries are eliminated:
- No worrying about whether one has allocated too many or too few servers
- No worrying about peak load capacity
- No worrying about operating system-level security
- No worrying about errors in the orchestration code
2. Managed high availability
Serverless is about making it “someone else’s problem” to keep your application up and running. This means that if a server running your application crashes in the middle of the night, that it shows up as an alert on someone else’s dashboard, and it is their responsibility to fix it before you even notice. There is still important work to be done to ensure that your application is always running and available, it’s just not being done by your team.
That being said, one should still “trust, but verify”. Implement your own uptime and performance tracking, and continually test the availability of your application. Your team is still responsible for the high availability of your application. You are just trusting that your serverless provider can detect and fix issues faster than you can yourself and that their systems will fail less often than infrastructure you would have built yourself.
3. Fine-grained billing by actual usage
Last, but not least, the property of serverless systems that is often used to sell it to executives, is that it often costs less, much less. Users of serverless systems pay based on the actual usage they get from the system, and not on resources kept on standby.
For example, if you are looking at a function as a service (FaaS) offering, and using it to automate a cron job that runs once a day, then one could end up paying a fraction of a penny per month, compared to $30-40 to keep a virtual server running that same month. That means a more than 3000x cost savings. Imagine if all your infrastructure costs were scaled down by that same multiple.
In a serverless system, one only pays for the useful work being done, at fine-grained level. There is no need to pay for idle or partially unused servers.
Example: SaaS Vendors
You may be surprised to discover that you are already using serverless systems. Software as a service (SaaS) vendors provide you with an abstraction which is serverless.
With a SaaS vendor, you just consume the benefit of their application, and how it interacts with your own systems, without worrying about the infrastructure that they use to implement it. Let’s see how it does with our three serverless properties:
- You don’t see or worry about their servers
- It’s the vendor’s responsibility to keep their service working
- Via economies of scale, it’s usually cheaper for them to provide the service than it would have been for you to build it yourself.
So, you may have been using a serverless approach all along. Whenever it makes more sense to buy technology than to build it, the serverless way to implement this is via a SaaS provider.
Other backend as a service (BaaS) providers such as Auth0 and Firebase would also fall under this example.
Example: Data Platform
At Retina, we process large datasets, and run machine learning models on them which require large amounts of computational power. To do this, we run Apache Spark, and use Databricks to handle automatically allocating, configuring, and connecting virtual servers to handle our distributed workloads.
To our data science team, this happens completely transparently, without them having to think about servers. And, when the servers are no longer being actively used, they spin down, reducing costs.
Example: Backend Functions
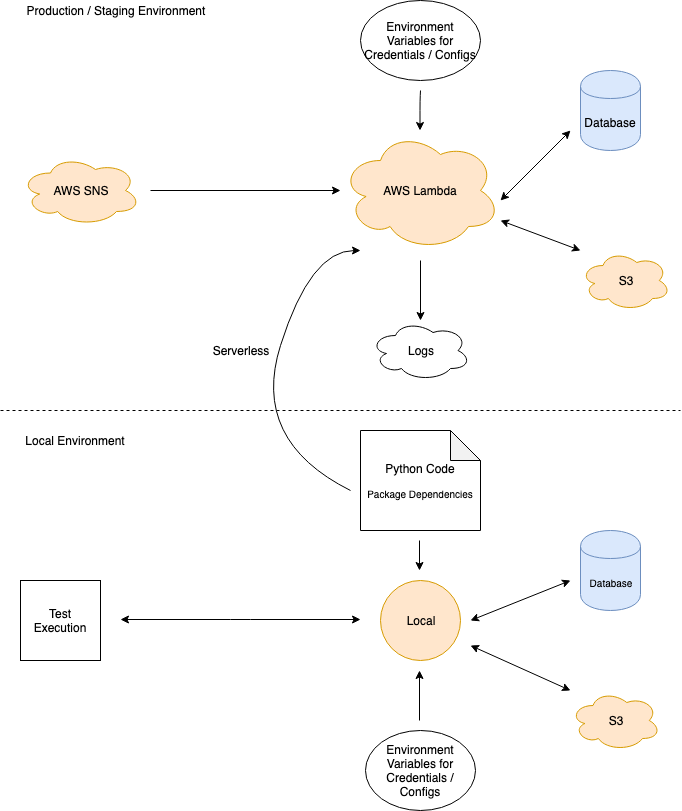
At Retina, we use additional backend functions in Python to orchestrate the logic for various automated data processes. For this, we make use of the Serverless Framework (and some plugins, and deploy to AWS Lambda in a more “traditional” serverless approach.
We use the AWS SNS message queue service to trigger these functions without having to manage our own infrastructure. This serverless approach lets us execute these functions securely and reliably.
When developing these functions, we take a few steps to write this in a “serverless” mindset. We ensure that all persistent state is stored in databases, or S3, outside of the execution environment of the functions. Functions are also designed to be idempotent, so that they can be logically executed more than once without creating inconsistent state. We also setup local test environments to test the majority of our code before it is deployed.
Example: Full-Stack Web Application
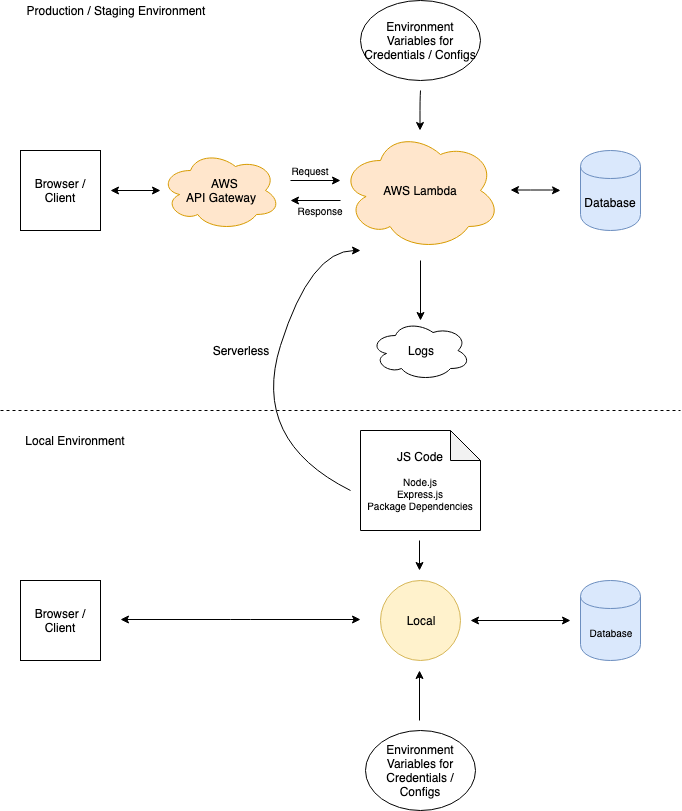
One of the interesting use-cases that we implement in a serverless architecture is our primary web application. For this, we use Vue and Nuxt rendered via Express. The application is then deployed, again via the Serverless Framework (with more plugins), to have HTTP requests to the AWS API Gateway trigger Express routes and render both the page being requested, and the precompiled and packaged JavaScript code to render the full web application.
We may end up going into more detail about this later in another blog post, but the end result is a deployed web application that scales. When there is additional web traffic, more resources are automatically allocated by AWS to handle that traffic in a highly available form. When the traffic dies down, as in staging environments, our costs also go down to mere pennies a month.
Thinking Serverless
Serverless is a way of thinking about technology resources that is incredibly powerful and flexible. Serverless is an abstraction bigger than any one technology or service. It’s also both an old idea, and a new one.
Hopefully this has helped inspire you to incorporate serverless thinking into your own technology choices. It is a great way to empower engineering teams to focus on delivering business impact. It is also cost-effective, and can be done with reduced vendor lock-in via the use of open source frameworks.
At Retina, we use serverless technologies to develop and deliver our data science products. If this excites you, we are hiring!