The most popular and commonly used customer lifetime value (CLV) models benchmark their strength on aggregate metrics. When compared at the aggregate level, many of these CLV models only differ by a few percentage points in terms of accuracy. When viewed this way, it’s easy to justify not switching to a new, more complex CLV model.
The problem is that aggregate statistics can hide how strong (or weak) a CLV model actually is. Many of these popular models become incredibly inaccurate at the individual level. Some companies may believe they are using an accurate model, when in fact the focus on aggregate metrics hides shortcomings at the individual level. This becomes an issue because most business use cases require a strong CLV model at the individual level, not just at the aggregate.
Business Use Cases for CLV Models
We should consider the true application of CLV models to help solve business problems. All of the follow use cases require individual CLV metrics:
- Facebook audience generation
- LTV cohort analysis
- Customer service ticket ordering
- LTV marketing lift
- CAC bid capping marketing
- Retention campaign prioritization
- Discount campaigns for high LTV customers
- Enhanced buying experiences for high LTV customers
- Loyalty programs
- Segmentation for marketing
On the flip side, the business cases that can settle for aggregate level CLV include:
- Average LTV over time
- Marketing LTV/CAC ratio
- Board reporting
From a business standpoint, it makes sense to prioritize models that calculate and predict CLV at the individual level to make the most of the metric. Let’s explore the data to support this statement next.
Technical Issues with Aggregate CLV
When you rely on aggregate metrics and ignore the individual-level inaccuracies, you are missing a large part of the technical narrative. Consider the following example of 4 customers and their 1 year CLV:
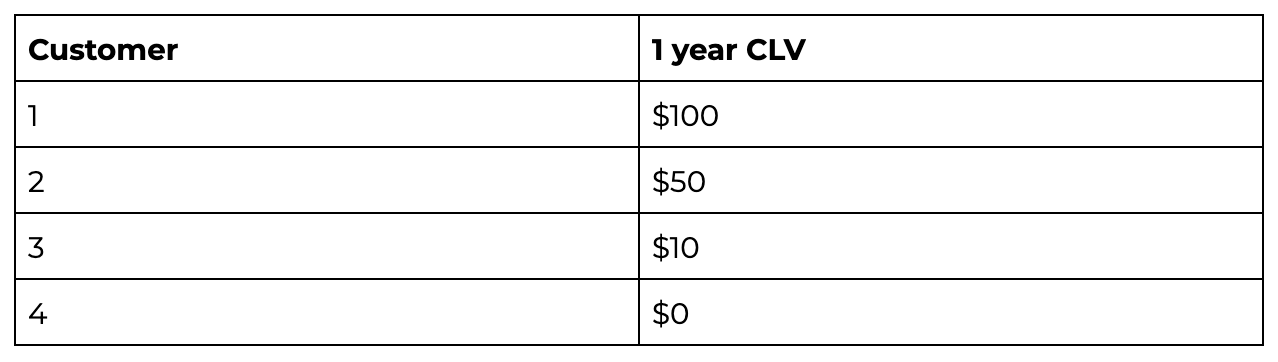
This example includes high, low, and medium CLV customers, as well as a churned customer, creating a nice distribution for a smart model to capture.
Now, consider the following validation metrics:
MAE: Mean absolute error
MAPE: Mean average percent error
ARPE: Aggregate revenue percent error
MAE and MAPE are on the customer level, while ARPE is an aggregate statistic. The lower the value for these validation metrics, the better. This example will demonstrate how an aggregate statistic can bury the shortcomings of low-quality models.
To do so, compare a dummy model guessing the mean to a CLV model off by 20% across the board.
Model 1: The Dummy
The dummy model will only guess $40 for every customer.
Model 2: CLV Model
This model tries to make an accurate CLV prediction at the customer level.

We can use these numbers to calculate the three validation metrics.

This example illustrates that a model that is considerably worse in the aggregate (the CLV model off by 20%) is actually better at the individual level. The CLV Model has better MAE and MAPE metrics, while the ARPE has the better ARPE metric in this example.
To make this example even better, let’s add some noise to the predictions.
# Dummy Sampling: # randomly sampling a normal dist around $40 with a SD of $5 np.random.normal (40,5,4) (44.88, 40.63, 40.35, 42.16) #CLV Sampling: # randomly sampling a normal dist around answer with a SD of $15 max (0, np.random.normal (0,15)), max (0, np.random.normal (10, 15)), max (0, np.random.normal (50,15)), max (0, np.random.normal (100, 15)), (0, 17.48, 37.45, 81.41)

The results above indicate that even if an individual stat is a higher percentage than you would hope (25% error seems quite high for the “correct” CLV model), the distribution of those CLV numbers is more in line with what we are looking for: a model that distinguishes high CLV customers from low CLV customers. If you only look at the aggregate metrics for a CLV model, you are missing a major part of the story, and you may end up choosing the wrong model for your business.
Based on proprietary models built at Stanford and UCLA, Retina is the only customer intelligence partner that can accurately calculate CLV early in the customer journey, at or even before the first transaction. We focus on individual level customer lifetime value metrics because they are the most useful and transformative for your business. Contact us at [email protected] to learn more.