Customer segmentation is a powerful technique for understanding your customers. However, it can be tricky to successfully implement it in a business context.
In this blog post, we will describe two business applications for customer segmentation. We also will list some common machine learning models from the vantage point of each functional goal. Finally, we’ll conclude with some general suggestions for crafting your own approach.
Two goals for customer segmentation
Why segment customers? When you group customers together, it’s possible to infer behavior by looking at the rest of the group. But, the nature of the inference will depend on your ultimate business goal.
Describe your customers – First, you may seek to understand who your customers are in a holistic sense. You may ask yourself, “What’s typical for someone in this segment?” To intuit a response to this question, you could look at known features and attributes for all customers assigned to the segment.
You may also ask yourself, “How are my customers different from one another?” In this case, you would look at those same features — but seek the ways in which they differ from one another across segments.
The unifying theme is that these questions seek descriptive answers. We can use them to interpret a segment as a typical customer, or archetype. You can interpret the relative segment size as the proportion of customers who act like that particular archetype.
Predict customer behavior – On the other hand, you may not care about who your customers are, but rather what they will do. In other words, you seek to predict customer behavior.
For example, you may want to use segmentation to predict the ROI for a marketing campaign under the assumption that similar customers will react in a similar way to the same campaign.
How goals influence models – Predictive segmentation differs from descriptive segmentation in the way we measure model performance. Segmentation is an unsupervised learning model, so labels for evaluating model performance are not fixed. Rather, we must choose to monitor error for one or more features in the data set: Monitoring one will keep its error low at the cost of the others; monitoring all features will result in higher error, but the error will be roughly equally distributed.
Below, we will describe some common models for customer segmentation. Some models are particularly adept at descriptive tasks; others for predictive. Where this isn’t obvious, we will point out the setting for which the model works best.
Group by features
Let’s start with some simple examples. The approaches below are so common, they serve as a foundation and motivation for the models that follow.
Group by time
A simple approach to grouping cohorts is by customer start date. Using this method, you can capture time-sensitive effects like seasonality, brand awareness over the course of a media campaign, and stage of business development.
For example, customers who convert during the holiday season are likely motivated by the same cultural forces that drove engagement for the cohort 12 months prior. Yet, those acquired through a coordinated media rebranding should be considered separate from veteran customers.
Typically, a month is the length of time chosen to delineate new cohorts, but the length should ultimately depend on the average engagement frequency and customer lifecycle.
Group by value
Cohort segmentation by join date doesn’t account for all customer variation; we expect differences among customers who convert in the same month, as well as similarities among some customers from different cohorts.
We get a holistic view of customers when we segment by value. For example, the most valuable customers are known as “whales.” It’s possible to learn how to attract and retain them by viewing their behavior as a group.
At Retina, we offer a free service, Retina Go! that scores individual customers by their Customer Lifetime Value (CLV) and likelihood to churn. We also assign your customers to one of six segments: active, at risk, or inactive for each of high and low CLV.
Group by concurrent features
Grouping by a single metric is easy, as there is typically a natural ordering. When you segment by several attributes at once, you should invent a criterion for each customer to measure distance to all possible segments. Then, assign each customer to the closest segment.
For instance, let’s assume we seek to segment customers into four groups:
(i) those who prefer product A and engage through email
(ii) those who prefer product A and come through mobile interstitials
(iii) preferrers of product B who engage through email
(iv) those who prefer product B, but come through mobile.
Since any given customer may use both products and both channels, one criterion for each segment is the sum of product and channels touches. Another criterion is the sum of product and channel ratios. Your choice of criterion will affect the segment assignments, but not the segment definitions.
Learn features by which to group
Machine learning is handy for choosing what your segments should be, in addition to helping you identify customer assignments. The approaches below are typically called “unsupervised” or “unstructured” learning, but it’s possible to use traditional supervised methods as well.
Hierarchical clustering
This segmentation approach will start by placing each customer in his or her own segment. Next, the algorithm iteratively “merges” the closest pairs together to reduce the number of segments by one. This is repeated until the desired number of segments is achieved. The graph below represents this process.
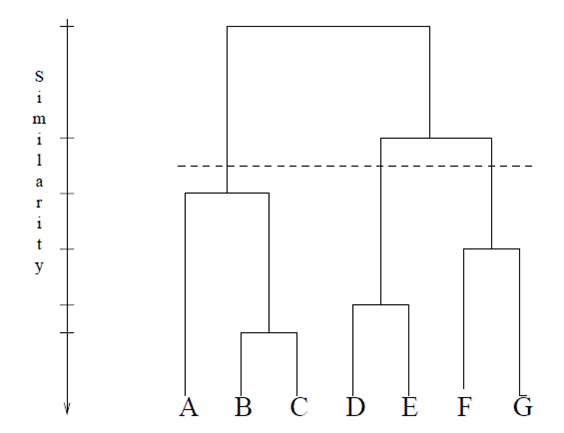
Hierarchical clustering requires a way to measure the distance between customers, including the sets of customers. We’ve explored some of these already, although in the context of a fixed segment. Now, we will measure the distance between segments in order to identify the closest pair and conjoin them.
When the desired number of segments remain, they’re considered highly representative of a particular set of customers. This algorithm is “greedy” because it takes small local steps to decrease the number of segments.
Criterial clustering
By contrast, criterial clustering will use a hypothetical archetype to represent an entire segment. The model assigns customers to the segment with the closest archetype. As before, this approach requires a distance measure; now it must be defined for any hypothetical customer who may exist.
The K-means algorithm is a well-known example of criterial clustering, and its distance metric is the sum of squared error. Likewise, K-medoids clustering uses the sum of absolute error as its distance metric.
Criterial clustering is considered a “global” algorithm, because it finds (or tries to find) the best segmentation for whatever distance measure and customer data set you provide. Unlike hierarchical clustering, you must choose the number of segments beforehand.
Decision trees
Finally, a decision tree will assign customers to leaves, or end nodes, of its branches. Each branch splits a group of customers into two subgroups in a way that minimizes the prediction error. Typically, a decision trees splits into many leaves. Then, the algorithm reconstructs a segment after the fact by joining leaves with the same predicted label.
Decision trees split at the branches according to some rule, which measures data fit using two disjoint sets. Then, it chooses the split that performs best. The choice of measure may be predictive (e.g., label prediction error) or descriptive (e.g., entropy).
Hierarchical models and decision trees are counterparts to one another: The former joins small segments into larger ones; the latter splits larger segments into smaller ones.
Common issues and best practices
As with most data science projects, customer segmentation using real data is more difficult than it first appears. Beware of the following sticky issues that often occur:
- Missing data: When your data set has missing or unknown entries, some models will just not work. Stick to criterial clustering, and read up on how to cluster even when your data is messy.
- Measuring success: What criterion should you choose for comparing categories? What about for comparing behavior over time? How do you know your segments are good enough? Answering all of these questions requires a deep understanding of cluster coherence, silhouette scores, and mutual information.
- Scalability: Most clustering methods are not very fast because they require iterating over large datasets several times. In most cases, it’s possible to parallelize across rows, and then across columns, in an iterative fashion. Leveraging a parallel architecture is the only way to scale to massive levels. (see our dataops blog post)
- Stale models: As new data comes in, it’s possible to update a segmentation using the old segments as a warm start, rather than starting from scratch every time. An “online model” is one that updates iteratively from a live data stream. This is only possible for hierarchical or criterial clustering, however.
Conclusion
We’ve now viewed a recipe for customer segmentation. The choice to use a hierarchical, criterial, or decision tree model should depend on your business problem, and whether it calls for you to describe or predict customer behavior. (Also, how you validate your work will depend on this as well.)
If you’re looking for workarounds for handling messy data or tips on how to scale to titanic audiences with parallel online algorithms, both of these challenges typically require input from entire teams. To make things easier, we at Retina are building tools to solve the issues that may arise from customer segmentation. If you’d like to learn more, you can schedule a demo with us.
Also, if you are a data scientist, and this sounds like what you are interested in doing, Retina is hiring!